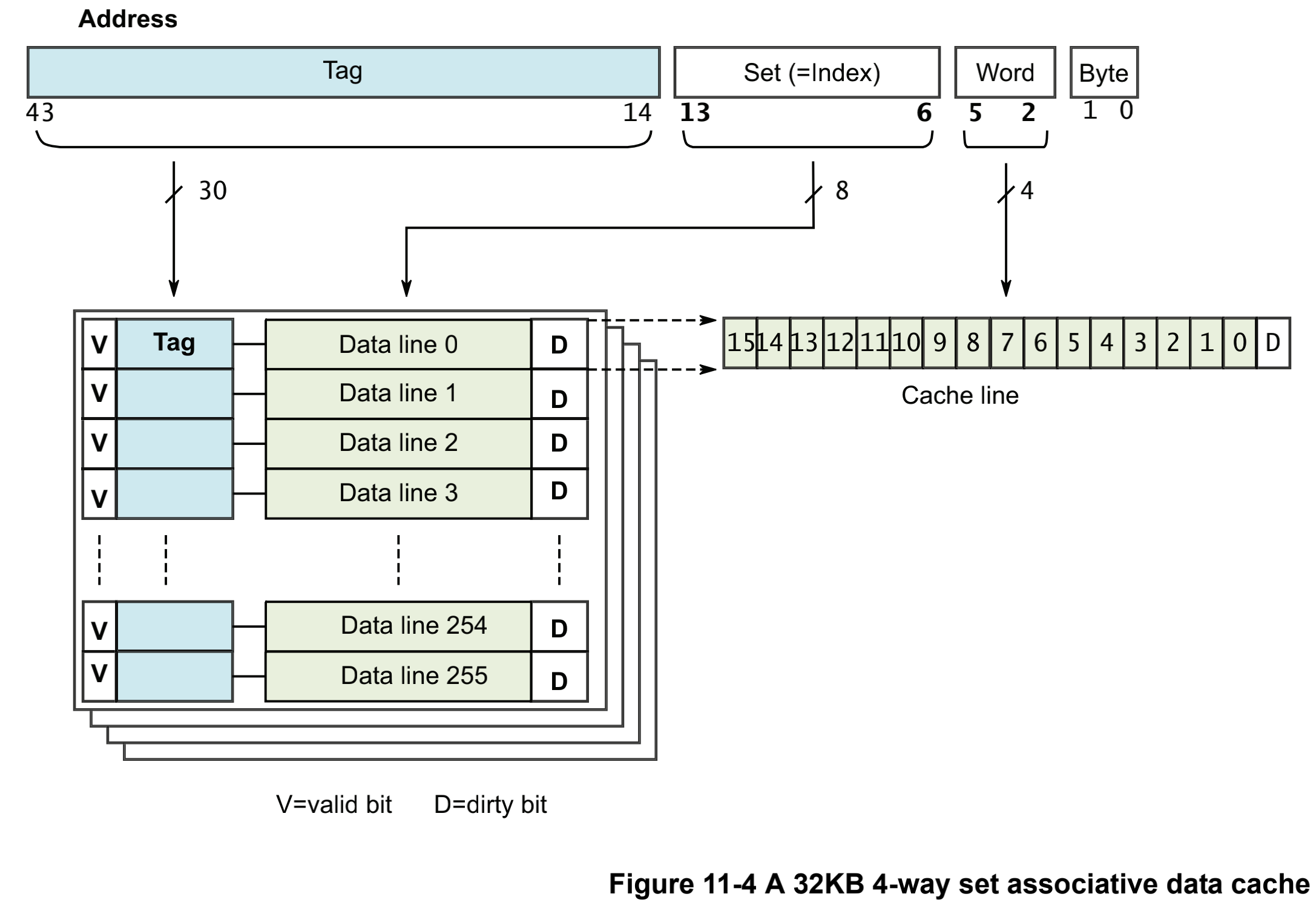
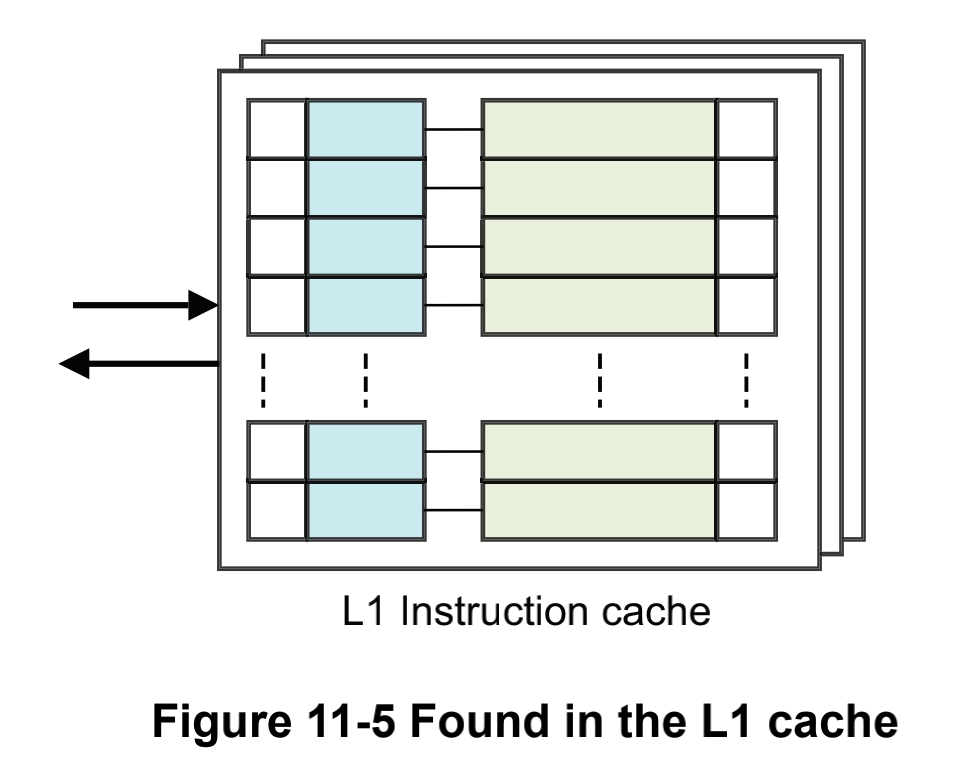
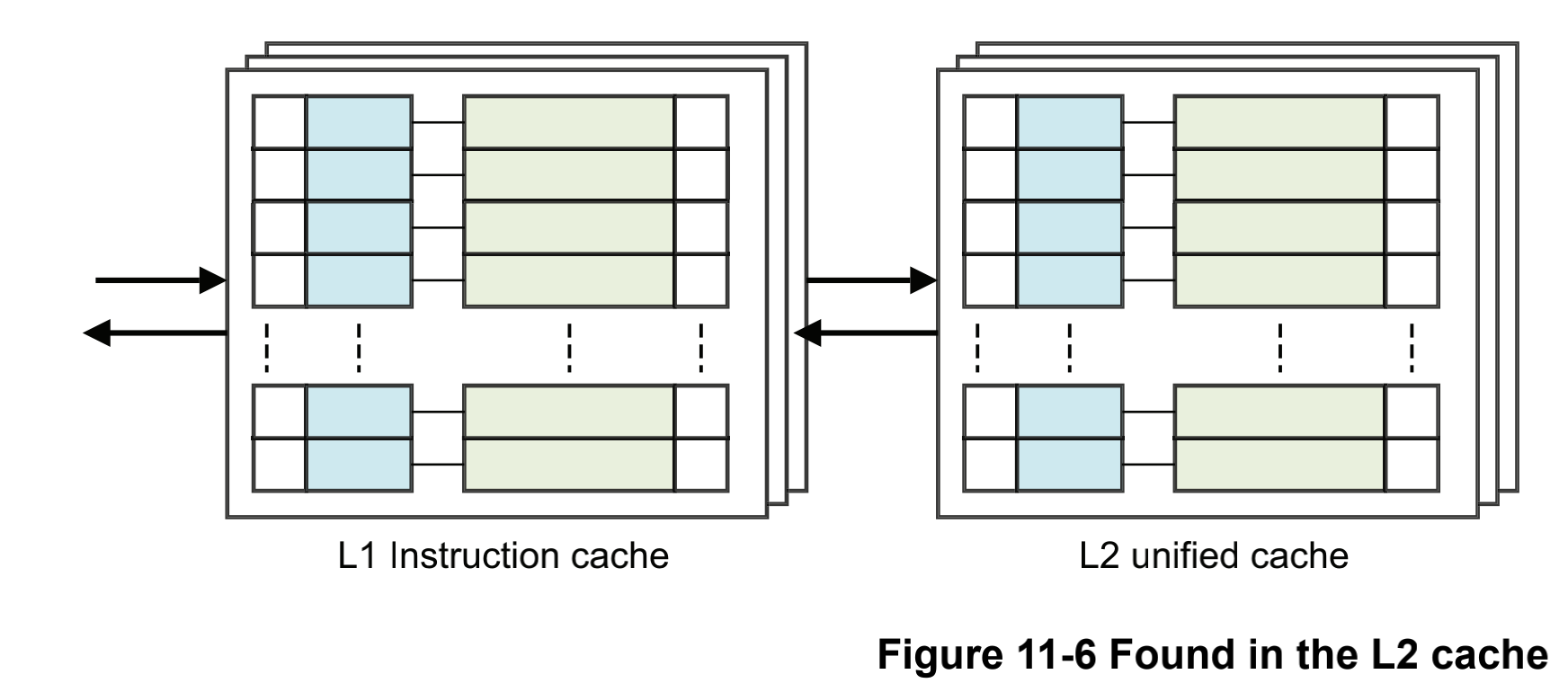
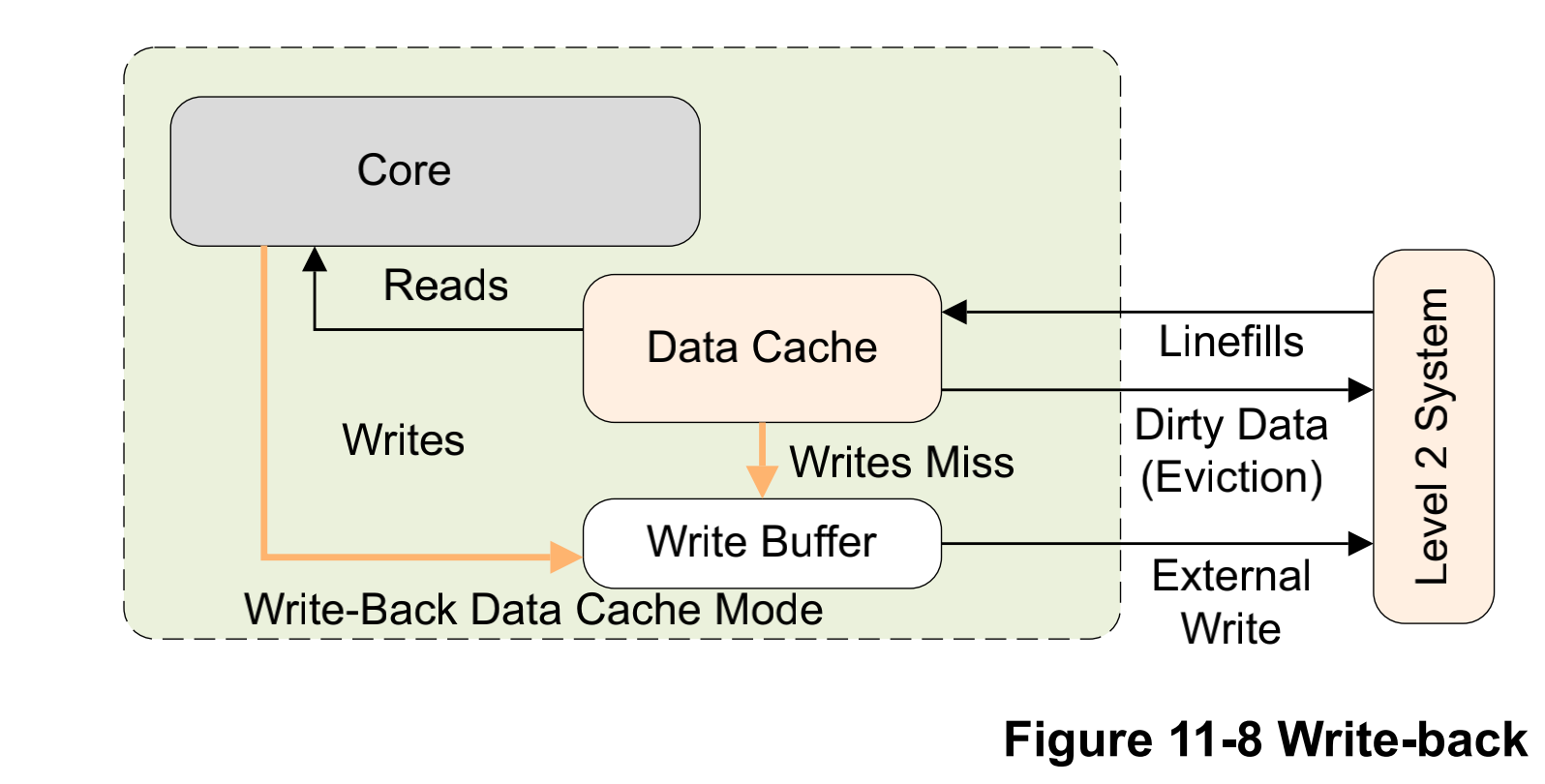
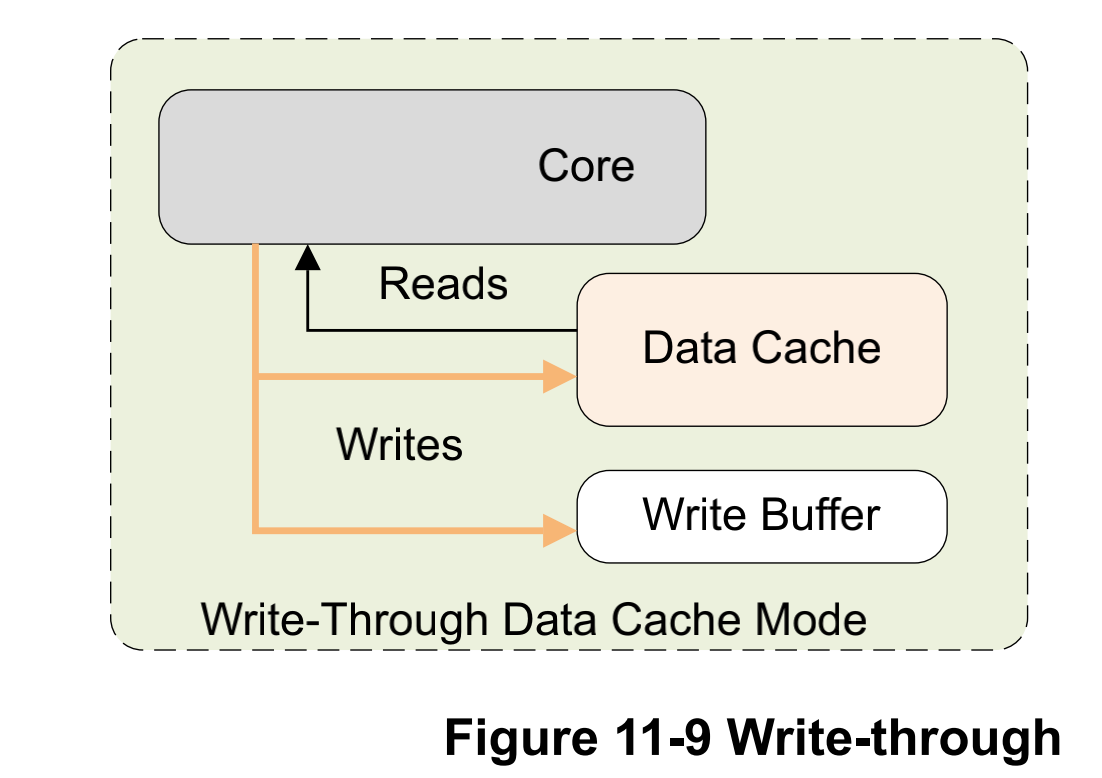
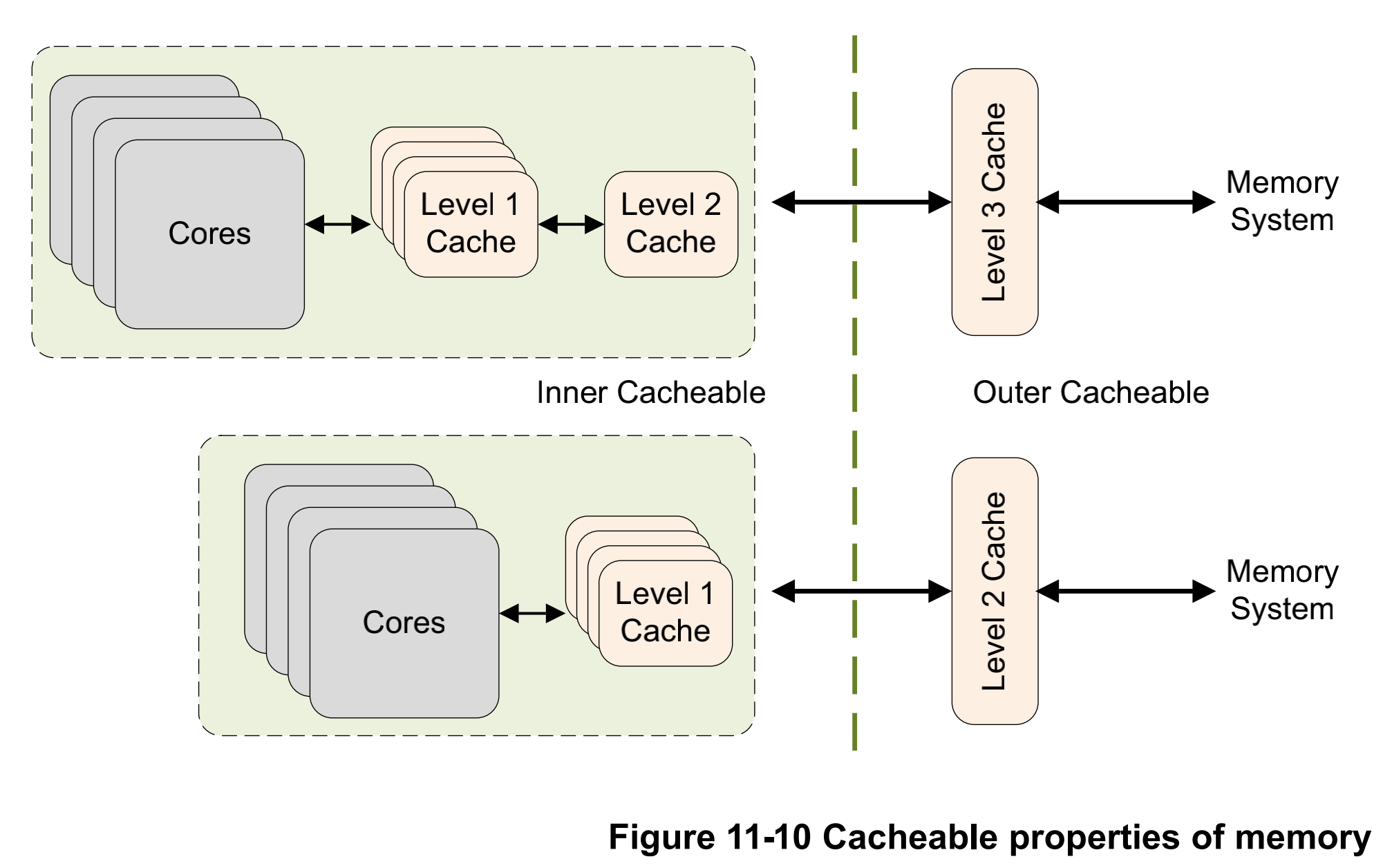
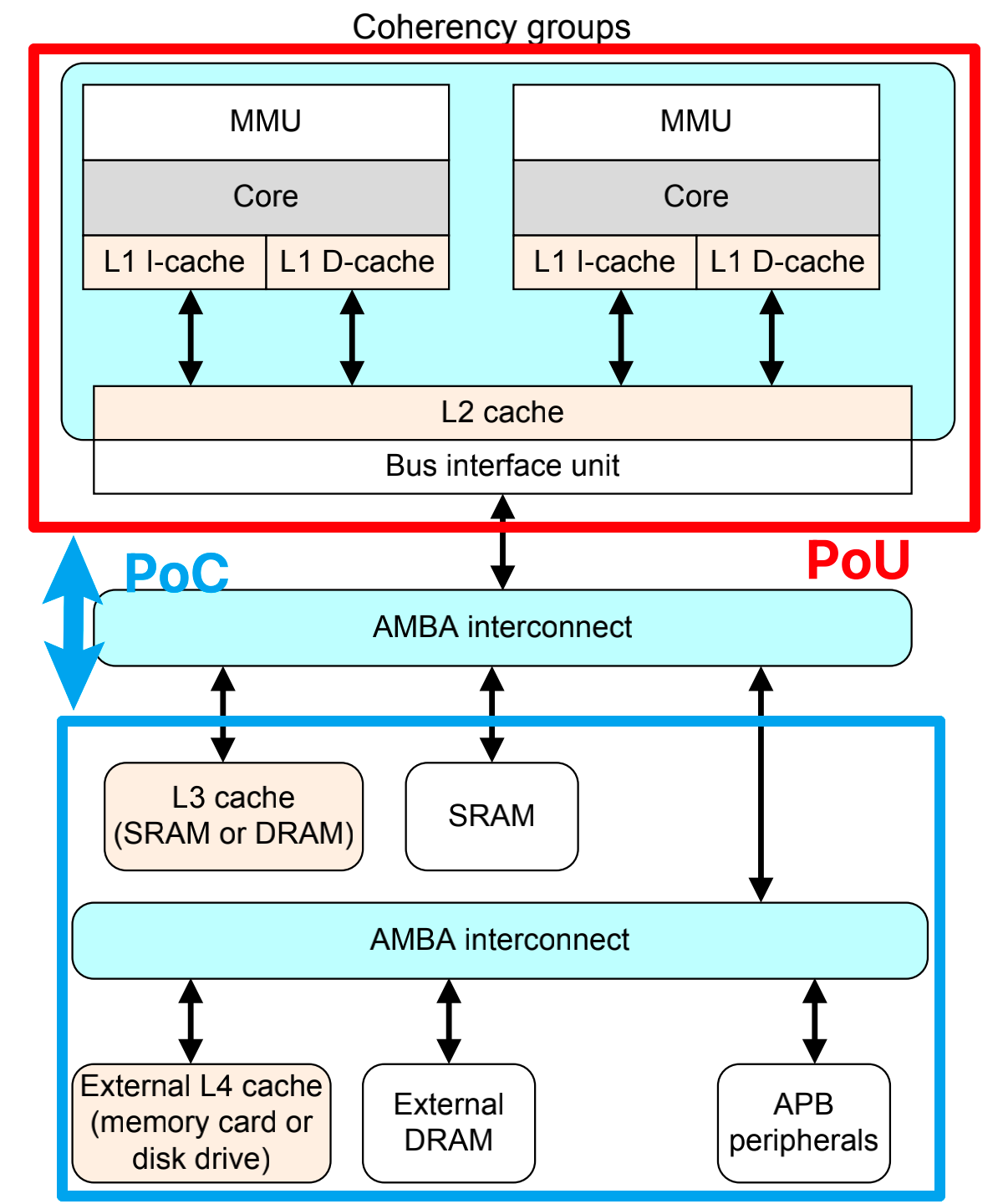
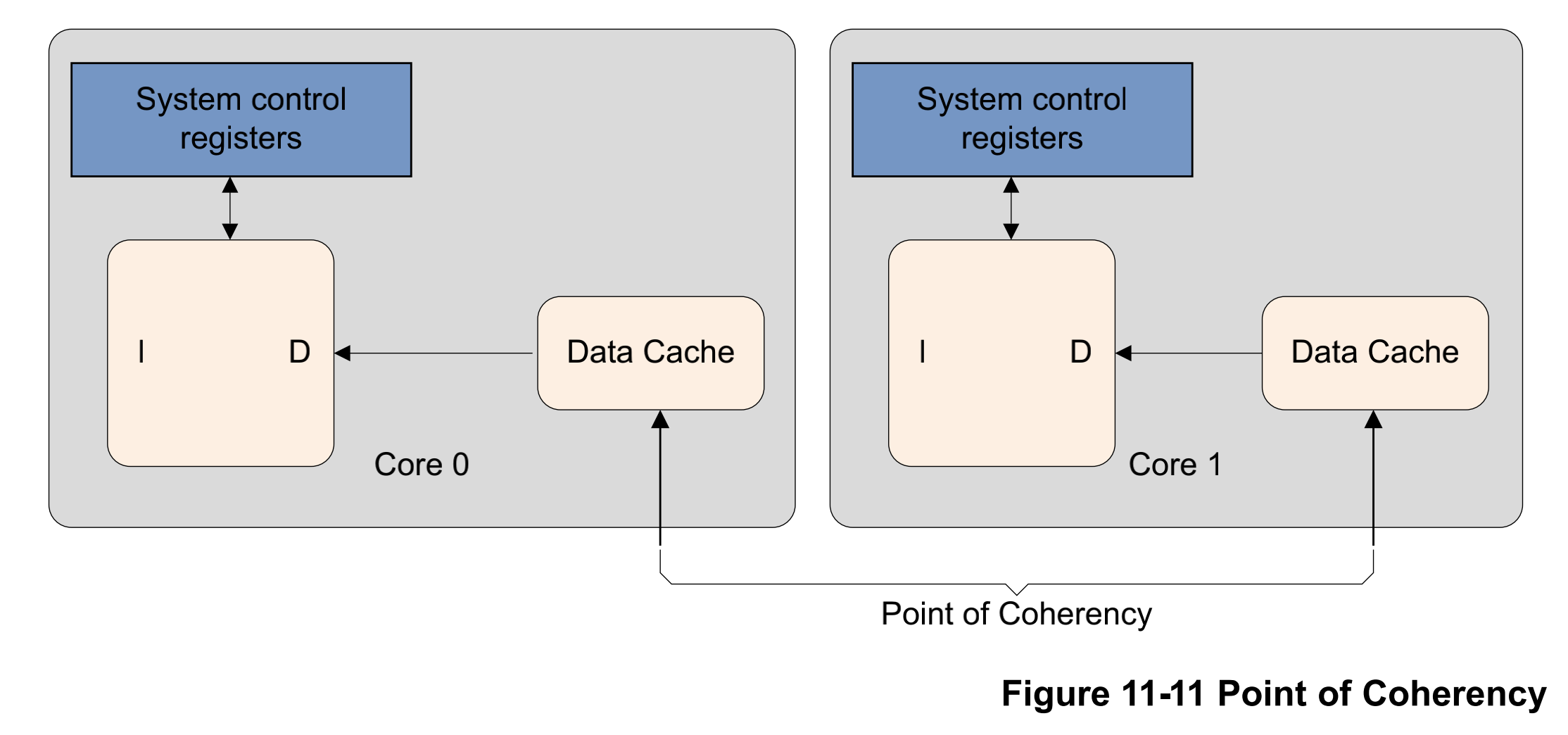
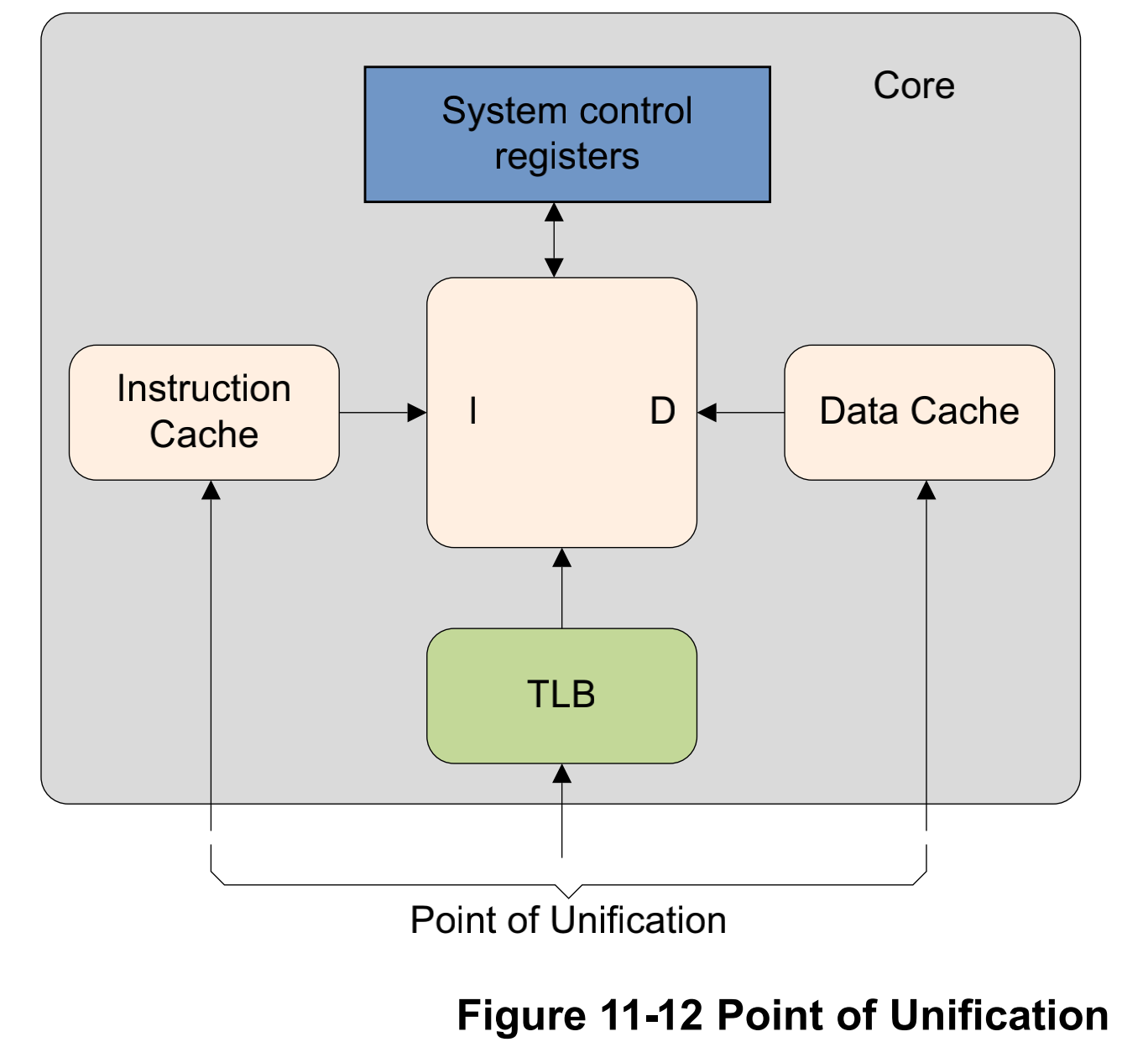
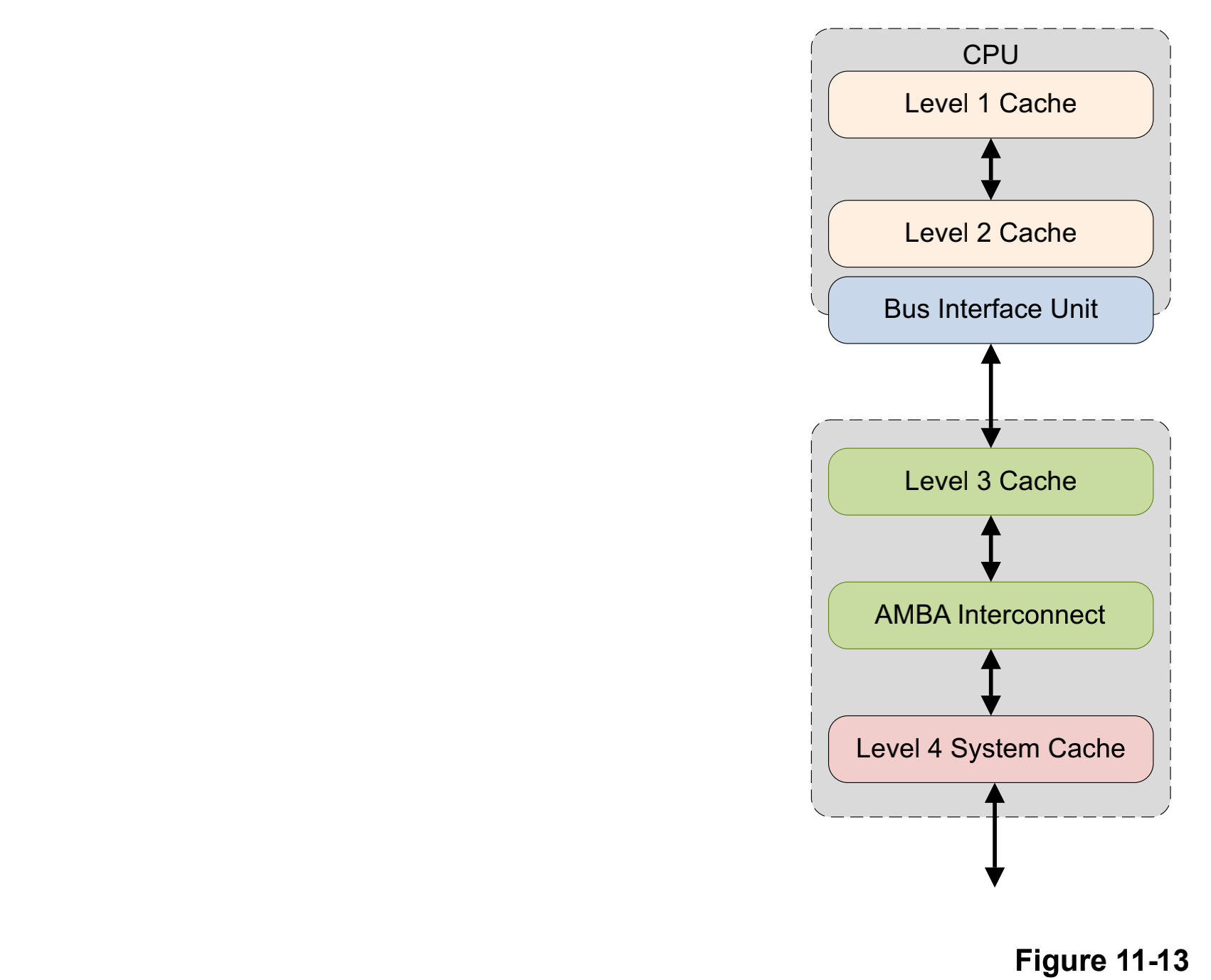
# 17\_ARMv8\_高速缓存(二)ARM cache设计
## *17\_ARMv8\_高速缓存(二)ARM cache设计*
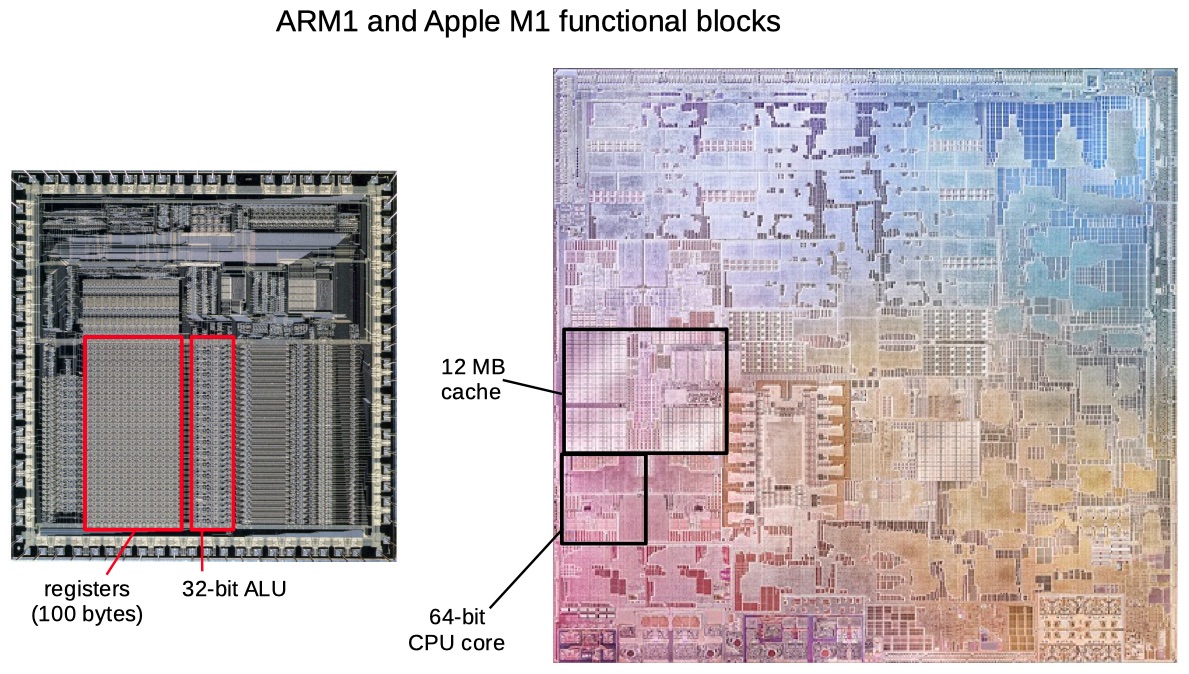
> Looking at the ARM1 die, you see functional blocks such as 100 bytes of registers and a basic 32-bit ALU. On the M1 die, similar-sized functional blocks are a 12-megabyte cache and a complete 64-bit CPU core. It shows what Moore's law has done over 35 years.