07_ELF文件_堆和栈调用惯例以ARMv8为例
https://github.com/carloscn/blog/issues/50
07_ELF文件_堆和栈调用惯例以ARMv8为例
1 栈与调用惯例
1.1 栈的概念
栈和堆的概念非常重要,程序员的修养是以x86架构讲的堆栈的概念,我们以ARMv8 AArch64为主来研究一下堆栈。

栈的概念我们可以重力翻转之后的桌子上的一摞书为例子,栈顶就是最下面眼镜的位置,栈底就是桌子。栈的顺序就是我们最后放的眼镜,是先被拿出来的。栈(stack)是一种数据结构,计算机里面的栈使用栈数据结构管理内存。为什么要将“重力翻转”?因为栈是一种从高地址向低地址生长的存储结构,栈底对应高地址,栈顶对应低地址。

这里的SP被称为“堆栈帧(Stack Frame)”或者“活动记录(Activate Record)”。堆栈帧会保存以下记录:
函数返回地址和参数,如果传递参数≤8个,那么使用X0~X7通用寄存器来传递,当参数多于8个,需要使用栈来传递参数。
临时变量,例如局部变量
保存上下文
1.2 不同架构出栈和入栈
入栈过程:
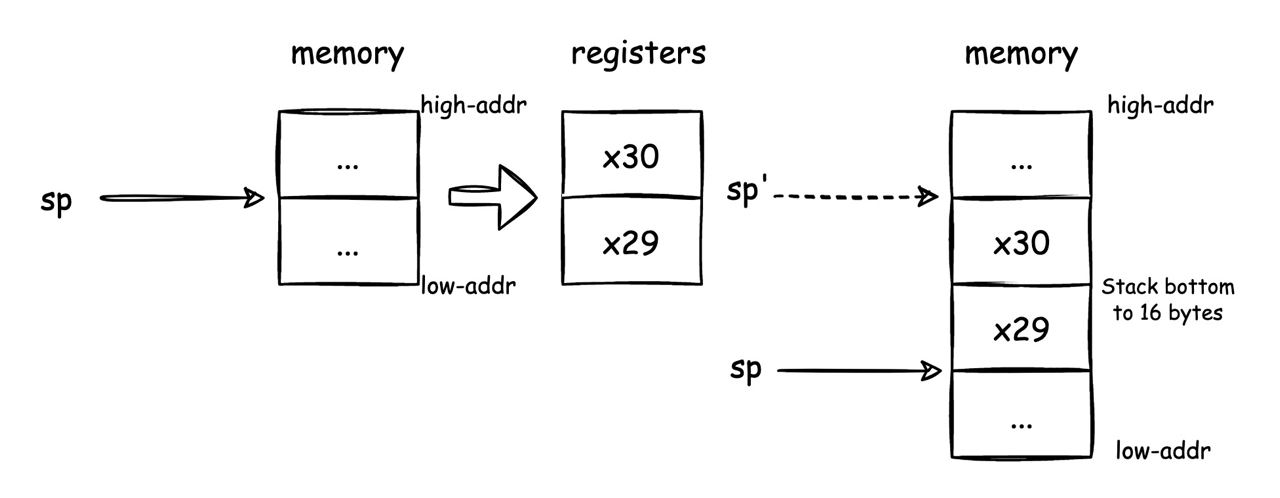
A32指令集提供了PUSH和POP指令来实现入栈和出栈,但是A64指令集已经去掉了PUSH和POP指令,只需要复用stp和ldp指令就可以实现入栈和出栈。
For example:
In this particular case, the stores could be combined:
However, in a simple compiler, it is not always easy to combine instructions in that way.
If you're handling w registers, the problem will be even more apparent: these have to be pushed in sets of four to maintain stack pointer alignment, and since this isn't possible in a single instruction, the code can become difficult to follow. This is what VIXL generates, for example:
这里AArch64实现入栈和出栈操作:
1.3 fomit-frame-pointer
使用aarch64-none-elf-gcc编译器参数-fomit-frame-pointer可以取消帧指针:
好处:不使用任何帧指针,直接计算变量的位置
坏处:无法trace,寻址变慢

使用fomit-frame-pointer的反汇编可以看到,123行sp已经不会备份到x29。
1.4 调用惯例Call convention
函数调用方和被调用方需要按照统一的协议去压栈和出栈,否则会有问题。调用惯例
函数参数的传递顺序和方式
栈的维护方式
名字修饰,默认是 _cdecl
__attribute__((cdecl))
1.4.1 函数参数压栈和出栈
我们定义一个这样的函数,有30个参数,看看arm编译器如何处理参数的压栈和出栈,另外对参数的类型也需要有观察。
这段函数的反汇编是:
A64: ARMv8 AArch64
A32: ARMv7 AArch32
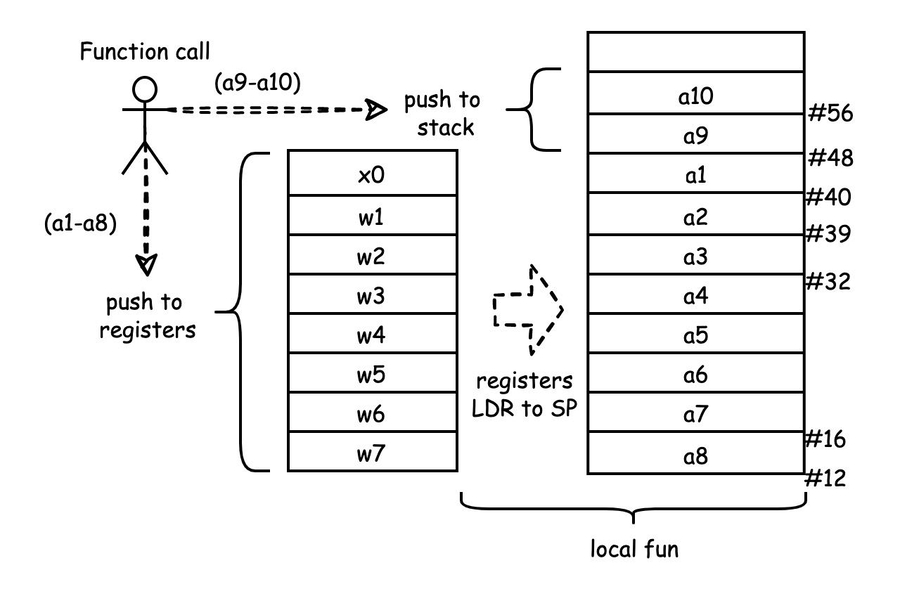
前8个参数被压入寄存器中,后面的参数被直接压到栈中。返回参数被放在x0中,返回地址在x30中。 参考:02_ARMv7-M_编程模型与模式
1.4.2 函数调用压栈和出栈
反汇编:
A64: ARMv8 AArch64
每个函数都在将sp - 16的位置,让栈向下增,栈空间逐步加大, 把x29和x30,栈指针和返回地址存入栈空间,然后函数返回后弹出栈。
A32: ARMv7 AArch32
1.4.3 ARMv8的函数调用标准
函数调用标准(Procedure Call Standard, PCS)用来描述父/子函数是如何编译、链接的,尤其是父函数和子函数之间调用关系的约定,如栈的布局、参数的传递、还有C语言类型的长度等等。每个处理器体系结构都有不同的标准。下面以ARM64为例介绍函数调用的标准(参考: Procedure Call Standard for ARM 64-bit Architecture )
ARM64体系结构的通用寄存器:
SP寄存器
SP寄存器
x30 (LR寄存器)
链接寄存器
x29 (FP寄存器)
栈帧指针(Frame Pointer)寄存器
x19~x28
被调用函数保存的寄存器,在子函数中使用时需要保存到栈中。
x18
平台寄存器
x17
临时寄存器IPC(intra-precedure-call)临时寄存器
x16
临时寄存器或第一个IPC临时寄存器
x9~x15
临时寄存器
x8
间接结果位置寄存器,用于保存程序返回的地址
x0~x7
用于传递子函数参数和结果,
2 堆与内存管理
堆的概念我们已经知道了,而且我们还用过大名鼎鼎的malloc函数,甚至malloc_align函数,但是我们似乎没有研究过在Linux里面malloc原理是什么样子的,在今天的这个topic我们再进一步的了解一下堆,后面我们在学习linux内核的内存管理的时候会更详细的讲解一下malloc如何实现的。
2.1 Linux进程堆管理
Linux进程地址空间,除了文件、共享库还有栈之外,剩余的未分配的空间都可以作为Heap的空间地址,堆和栈相反,堆是向上增长的。运行库向操作系统申请一批空间地址,又程序自己“零售”给内部程序。

Linux进程堆管理有两种方式:
brk()系统调用
mmap()
brk()系统调用实际上就设置进程数据段(data段+bss段的统称)的结束地址,如果我们将数据段结束地址向高地址不断滚动,那么扩大的空间就是我们可以用的heap的空间,glibc里面有个sbrk函数。
mmap()的作用是向操作系统申请一段虚拟内存地址,如果指定文件路径是可以将空间映射到文件,如果没有指定文件路径,那么就是匿名空间(Anonymous),匿名空间就可以作为堆空间。mmap可以指定申请空间的大小和起始地址,如果起始地址设定为0,那么mmap会自动跳转到合适的位置,申请的空间还可以指定权限。
glibc的malloc函数处理逻辑是这样的:
对于小于128KB的请求,它会在现有的堆空间分配。
对于大于128KB的请求,它会使用mmap函数为它分配一段匿名空间,然后再从匿名空间分配用户空间。
2.2 堆分配算法
空闲链表法
位图法
对象池法
2.3 堆碎片化问题
2.3.1 碎片产生
2.3.2 baremental/freeRTOS堆空间
嵌入式设备没有MMU,无法实现内存动态映射。所以没有操作系统兜底的嵌入式设备一定要小心,就算是有操作系统也要对内存分配了如指掌,否则就会出现意想不到的问题,内存碎片的问题就是很头疼的问题。
freeRTOS
freeRTOS对于堆的管理分为5个heap管理方式,十分复杂。
heap_1 - the very simplest, does not permit memory to be freed.
heap_2 - permits memory to be freed, but does not coalescence adjacent free blocks.
heap_3 - simply wraps the standard malloc() and free() for thread safety.
heap_4 - coalescences adjacent free blocks to avoid fragmentation. Includes absolute address placement option.
heap_5 - as per heap_4, with the ability to span the heap across multiple non-adjacent memory areas.
baremental
malloc和free并不能实现动态的内存的管理。这需要在启动阶段专门给其分配一段空闲的内存区域作为malloc的内存区。如STM32中的启动文件startup_stm32f10x_md.s中可见以下信息:
其中,Heap_Size即定义一个宏定义。数值为 0x00000800。Heap_Mem则为申请一块连续的内存,大小为 Heap_Size。简化为C语言版本如下:
在这里申请的这块内存,在接下来的代码中,被注册进系统中给malloc和free函数所使用:
在函数中使用malloc,如果是大的内存分配,而且malloc与free的次数也不是特别频繁,使用malloc与free是比较合适的,但是如果内存分配比较小,而且次数特别频繁,那么使用malloc与free就有些不太合适了。因为过多的malloc与free容易造成内存碎片,致使可使用的堆内存变小。尤其是在对单片机等没有MMU的芯片编程时,慎用malloc与free。
对于堆碎片化的问题,可以采用堆分配算法避免,比如内存池。
内存池,简洁地来说,就是预先分配一块固定大小的内存。以后,要申请固定大小的内存的时候,即可从该内存池中申请。用完了,自然要放回去。注意,内存池,每次申请都只能申请固定大小的内存。这样子做,有很多好处:
每次动态内存申请的大小都是固定的,可以有效防止内存碎片化。(至于为什么,可以想想,每次申请的都是固定的大小,回收也是固定的大小)
效率高,不需要复杂的内存分配算法来实现。申请,释放的时间复杂度,可以做到O(1)。
内存的申请,释放都在可控的范围之内。不会出现以后运行着,运行着,就再也申请不到内存的情况。
内存池,并非什么很厉害的技术。实现起来,其实可以做到很简单。只需要一个链表即可。在初始化的时候,把全局变量申请来的内存,一个个放入该链表中。在申请的时候,只需要取出头部并返回即可。在释放的时候,只需要把该内存插入链表。以下是一种简单的例子(使用移植来的linux内核链表,对该链表的移植,以后有时间再去分析):
2.4 使用malloc和free一些建议
不建议在中断中使用malloc。
线程不一定安全,在-pthread进行编译是线程安全的,在freeRTOS的heap_3.c中进行封装pvPortMalloc是安全的,但是在其他环境要持怀疑态度。
malloc不一定会成功,需要check结果
malloc和free一定要成对出现。
free之后给指针加NULL,防止野指针。
为了安全考虑,malloc之后的内存,需要memset置空后free掉,防止那块内存被分配可以读到数据。
3 Reference
最后更新于